Will the Need to Retrain AI Models from Scratch Block a Software Intelligence Explosion?
Citations
26th March 2025

This is a rough research note – we’re sharing it for feedback and to spark discussion. We’re less confident in its methods and conclusions.

Summary
Once AI fully automates AI R&D, there might be a period of fast and accelerating software progress – a software intelligence explosion (SIE).
One objection to this is that it takes a long time to train SOTA AI systems from scratch. Would retraining each new generation of AIs stop progress accelerating during an SIE? If not, would it significantly delay an SIE? This post investigates this objection.
Here are my tentative bottom lines:
- Retraining won’t stop software progress from accelerating over time.
- Suppose that, ignoring the need for retraining, software progress would accelerate over time due to the AI-improving-AI feedback loop.
- A simple theoretical analysis suggests that software progress will still accelerate once you account for retraining. Retraining won’t block the SIE.
- Retraining will cause software progress to accelerate somewhat more slowly.
- But that same analysis suggests that your software progress will accelerate more slowly.
- Quantitatively, the effect is surprisingly small – acceleration only takes ~20% longer.
- However, if acceleration was going to be extremely fast, retraining slows things down by more.
- Retraining means that we’re unlikely to get an SIE in <10 months, unless either training times become shorter before the SIE begins or improvements in runtime efficiency and post-training enhancements are large.
- Today it takes ~3 months to train a SOTA AI system.
- As a baseline, we can assume that the first AI to fully automate AI R&D will also take 3 months to train.
- With this assumption, simple models of the SIE suggest that you’re unlikely to complete the SIE within 10 months. (In the model, the SIE is “completed” when AI capabilities approach infinity – of course in reality they would reach some other limit sooner).
- BUT if by the time AI R&D is fully automated, SOTA training runs have already shortened to one month or less, then completing an SIE in less than 10 months is much more plausible.
- And improvements in runtime efficiency and other post-training enhancements (which I’m not modelling in my analysis) could potentially allow very fast takeoff without needing to retrain from scratch.
How did I reach these tentative conclusions?
Theoretical analysis
First, I conducted a very basic theoretical analysis on the effect of retraining. I took a standard semi-endogenous growth model of tech development, and used empirical estimates for the diminishing returns to software progress. This is the simplest model I know of to estimate the dynamics of an SIE – and by default it doesn’t account for retraining.
First, I conducted a very basic theoretical analysis on the effect of retraining. I took a standard semi-endogenous growth model of tech development, and used empirical estimates for the diminishing returns to software progress. This is the simplest model I know of to estimate the dynamics of an SIE – and by default it doesn’t account for retraining.
To understand how fast software progress1 accelerates, we can ask: how many times must software double before the pace of software progress doubles? This is a measure of how quickly software progress accelerates: lower numbers mean faster acceleration.
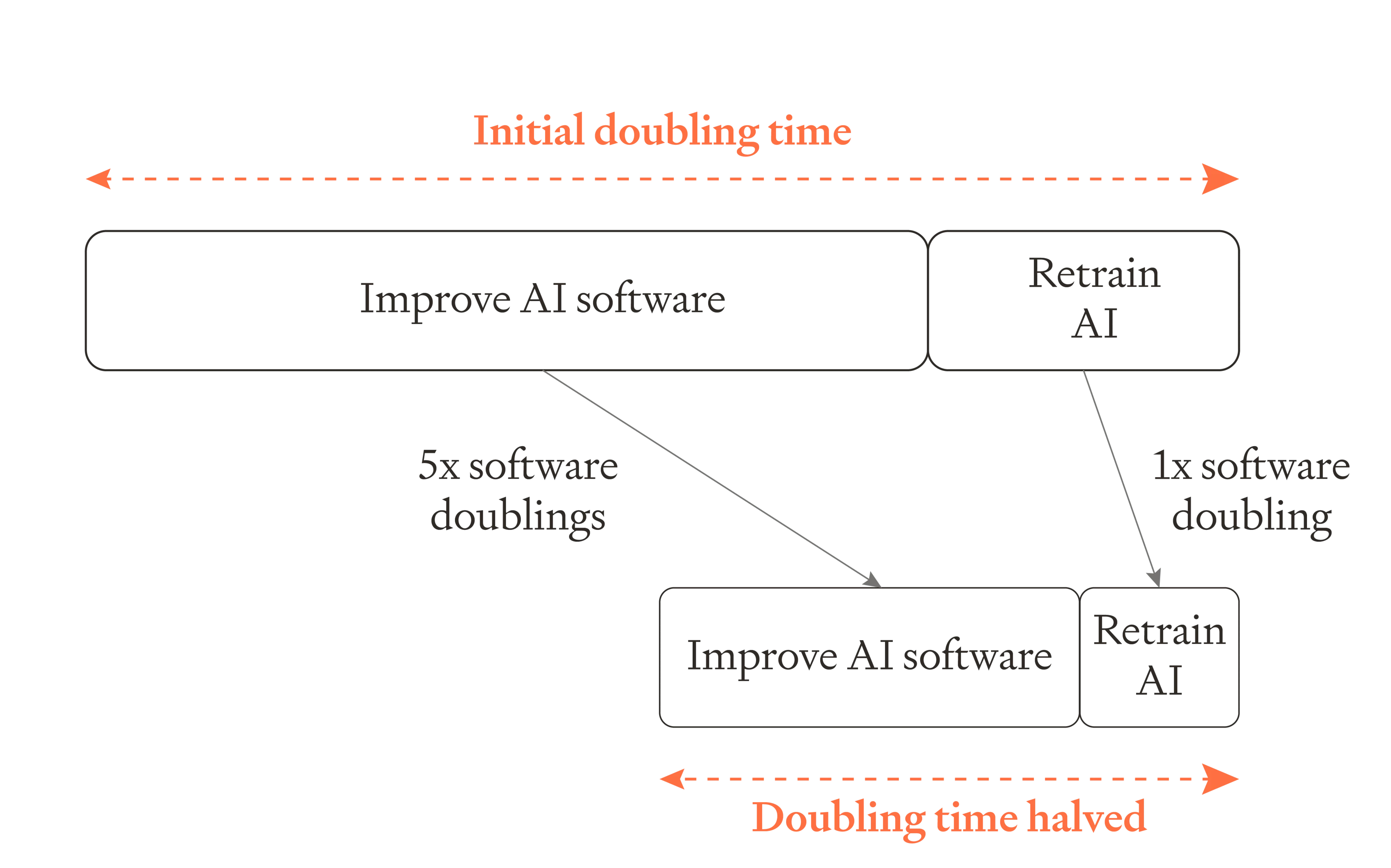
Without including retraining, my median parameters imply that once AI R&D is fully automated, software must double ~five times before the pace of software progress doubles. (There’s large uncertainty.)2 So progress accelerates gradually.
Accounting for retraining increases the number from five to six. Training runs get progressively shorter over time, and the SIE still accelerates but slightly more slowly. (See below for more explanation.)
Image
In a very aggressive scenario where software must only double once before the pace of progress doubles, retraining makes a big difference by increasing this to twice. So retraining makes a bigger difference to these aggressive scenarios, making them significantly less extreme.
Simple spreadsheet models
Second, I made very simple spreadsheet models of an SIE – again based on semi-endogenous growth models – one without retraining and one with retraining. Both sheets use the same parameters (other than whether to include retraining) and both calculate the time between the AI R&D being automated and AI capabilities going to infinity. I assumed that AI algorithms become 2X as efficient every month – that’s about ~10X faster progress than today.
Second, I made very simple spreadsheet models of an SIE – again based on semi-endogenous growth models – one without retraining and one with retraining. Both sheets use the same parameters (other than whether to include retraining) and both calculate the time between the AI R&D being automated and AI capabilities going to infinity. I assumed that AI algorithms become 2X as efficient every month – that’s about ~10X faster progress than today.
Results:
- If the initial training run lasts 100 days:
- The SIE takes about 3X longer with retraining
- The SIE lasts >10 months unless very extreme parameter values are used.
- If the initial training run lasts 30 days:
- The SIE takes about 2X longer with retraining.
- The SIE lasts >7 months unless very extreme parameter values are used.
(These slowdowns are longer than the slowdown predicted by the theoretical analysis because the theoretical analysis assumes that training runs get gradually shorter as the SIE gets closer, so are already very short at the point at which the spreadsheet model begins, and so have less of a slowing effect. See below for details.)

Theoretical analysis
Let’s estimate how quickly software progress will speed up excluding and including accounting for re-training.
Excluding retraining
We can ask: how many times must software double before the pace of software progress doubles? This is a measure of how quickly software progress accelerates: lower numbers mean faster acceleration.
We can ask: how many times must software double before the pace of software progress doubles? This is a measure of how quickly software progress accelerates: lower numbers mean faster acceleration.
In a separate piece, I estimate that the answer is very roughly 5. It could be as low as 2, or higher than 10.
Including retraining
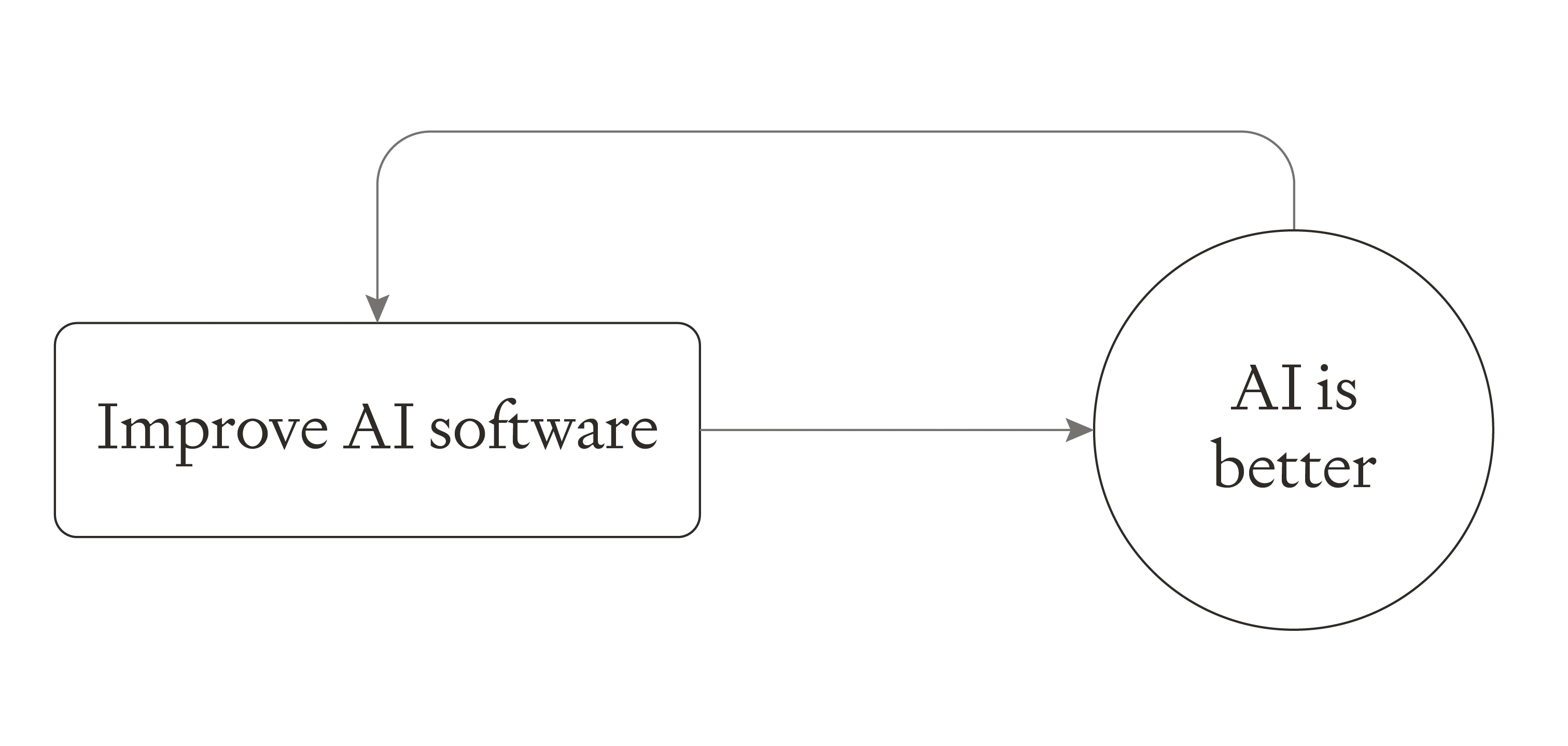
When we were excluding retraining, we were implicitly modelling AI progress as simply consisting of one step: improving AI software. Doubling the pace of AI progress simply involved doubling the speed of that step.
When we were excluding retraining, we were implicitly modelling AI progress as simply consisting of one step: improving AI software. Doubling the pace of AI progress simply involved doubling the speed of that step.
Image
Image
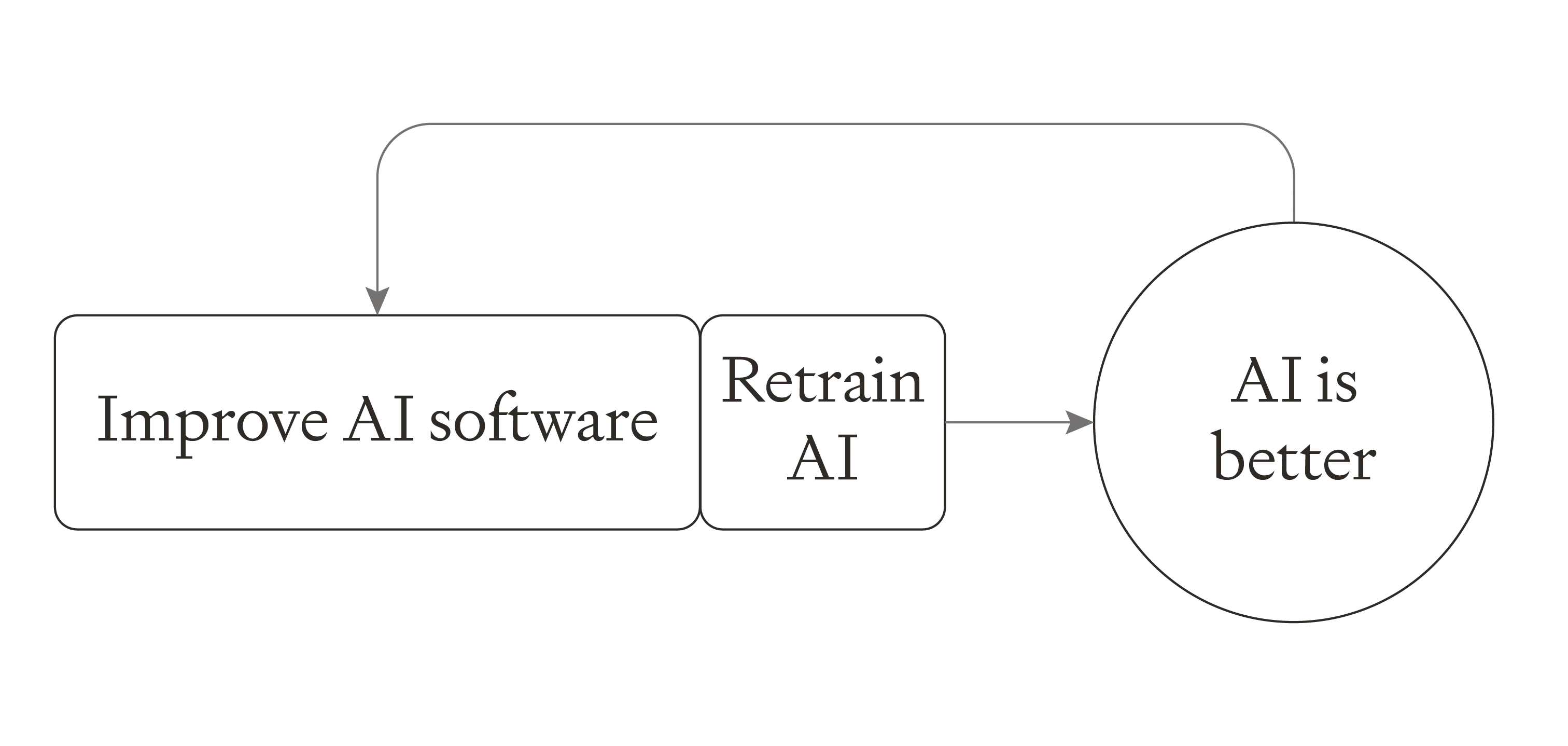
We expect the ‘improving AI software’ step take longer than the ‘retraining’ step. Today training runs currently take ~3 months but the gap between releasing frontier models is closer to 1-2 years. For this basic theoretical model, I’m assuming that the steps are serial. In reality, while you’re training the next model, you can still be making software progress, so the steps would overlap.
Now to doubling the pace of overall AI capabilities improvement requires doubling the speed of both steps.3 We must not just double the pace of software progress (as discussed above, this might take ~5 software doublings) but we must also halve the time taken to retrain AI.
Image
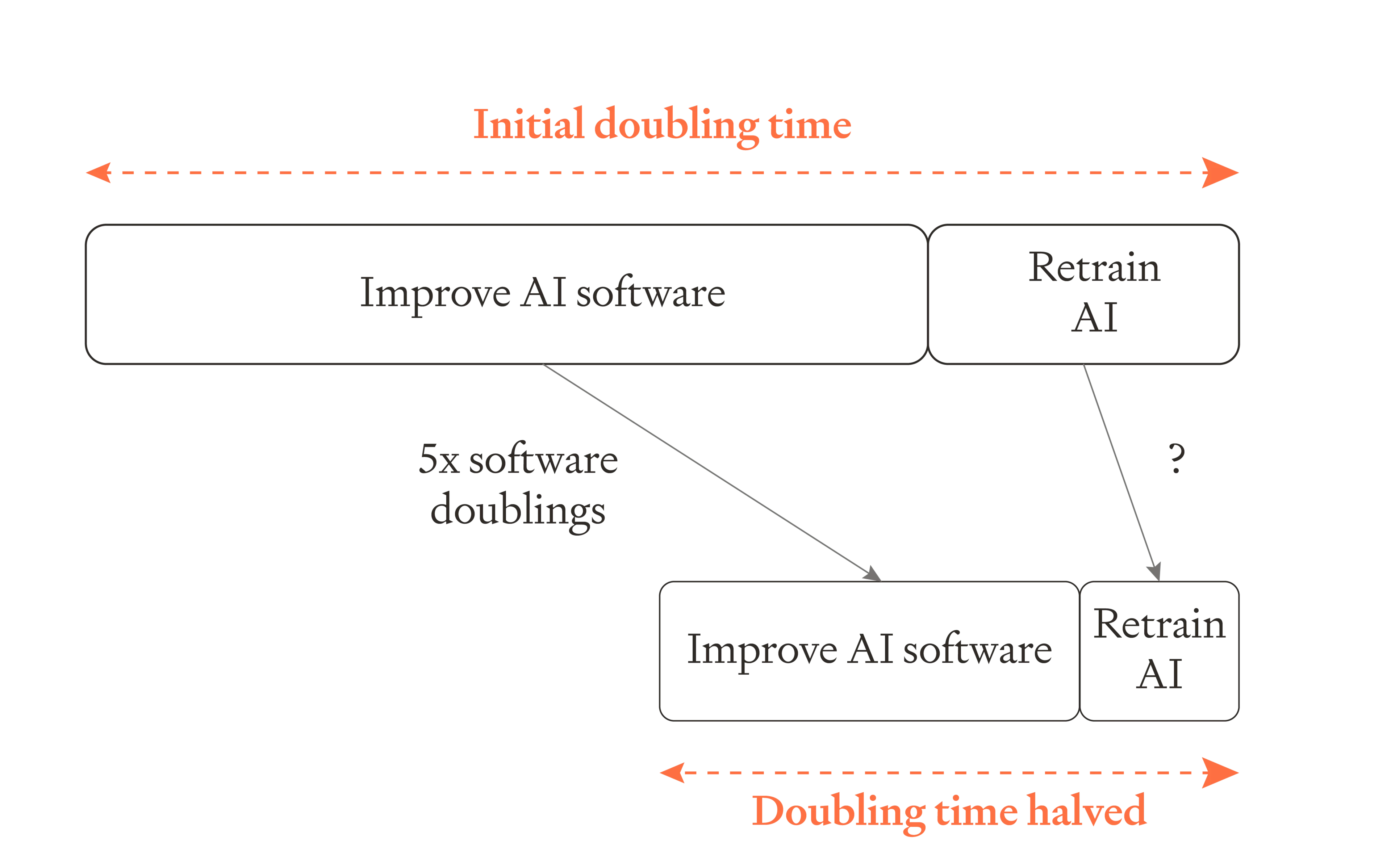
How can we halve the time to retrain AI? We can do this by 'spending' a 2X gain in training efficiency to make training faster rather than using it to make models smarter. That is, normally efficiency gains are used to train a model with more ‘effective training compute’, resulting in a smarter model. But instead we could use half as much training compute and train an equally smart model. This would allow us to train the model in half as much time (assuming we can parallelise training sufficiently – if we can’t, retraining could slow down an SIE much more).
So rather than doubling the pace of software development every ~5 software doublings, the pace will only double every ~6 doublings. The first 5 double the pace of software progress. The 6th isn't actually used to improve AI capabilities at all, but is just used to make training twice as fast.4
Image
All of this assumes my best-guess median parameters for accelerating software progress, in which it takes 5 doublings to double the pace of software progress. In a very aggressive scenario software would only need to double once before the pace of progress doubles, and retraining would increase this to twice. This makes the scenario significantly less aggressive. So accounting for retraining makes a small difference to the median scenario, but a significant difference to very aggressive scenarios.
The bottom line here is:
- If software progress was going to accelerate before taking retraining into account, it will still accelerate when retraining is accounted for.
- But software progress will accelerate more slowly than you would naively think.
- The slow down here is not very big unless the pace of acceleration would have otherwise been very rapid.

Toy model of the software intelligence explosion
I model a scenario where:
- AGI has just been trained using 1e29 FLOP.
- The training run took 100 days.
- The compute used for retraining is then reinvested to further improve capabilities.
In the model with continuous retraining, half of this compute is used to improve AI software (by finding better algorithms), and half is used to continually retrain the AI.5
In the model without continuous retraining, all of the compute is used to improve AI software (better algorithms can be applied instantaneously).
Software explosion with continuous retraining - model explanation
In this model, if all of the training compute were used to find better algorithms, cumulative software research would double in ~30 days. In fact I assume that only half of the training compute is used for this, so it would actually take ~60 days.
As training algorithms improve, the effectiveness of continuous training also improves. So initially each FLOP spent on training adds 1 effective training FLOP to the cumulative training run size, but after 60 days each FLOP adds 4 effective training FLOP to the cumulative training run size. There's little change to cumulative training run size over the first 60 days, because it's hard to make a big difference to the 100 days initially spent on training. After ~100 days, the effective training FLOP has increased more than 3X, because of the improved efficiency with which additional FLOP are increasing effective training FLOP.
| Days after training AGI | Cumulated effective training FLOP |
|---|---|
| 60 days | 1.6E+29 |
| 100 days | 2.5E+29 |
| 200 days | 1.3E+30 |
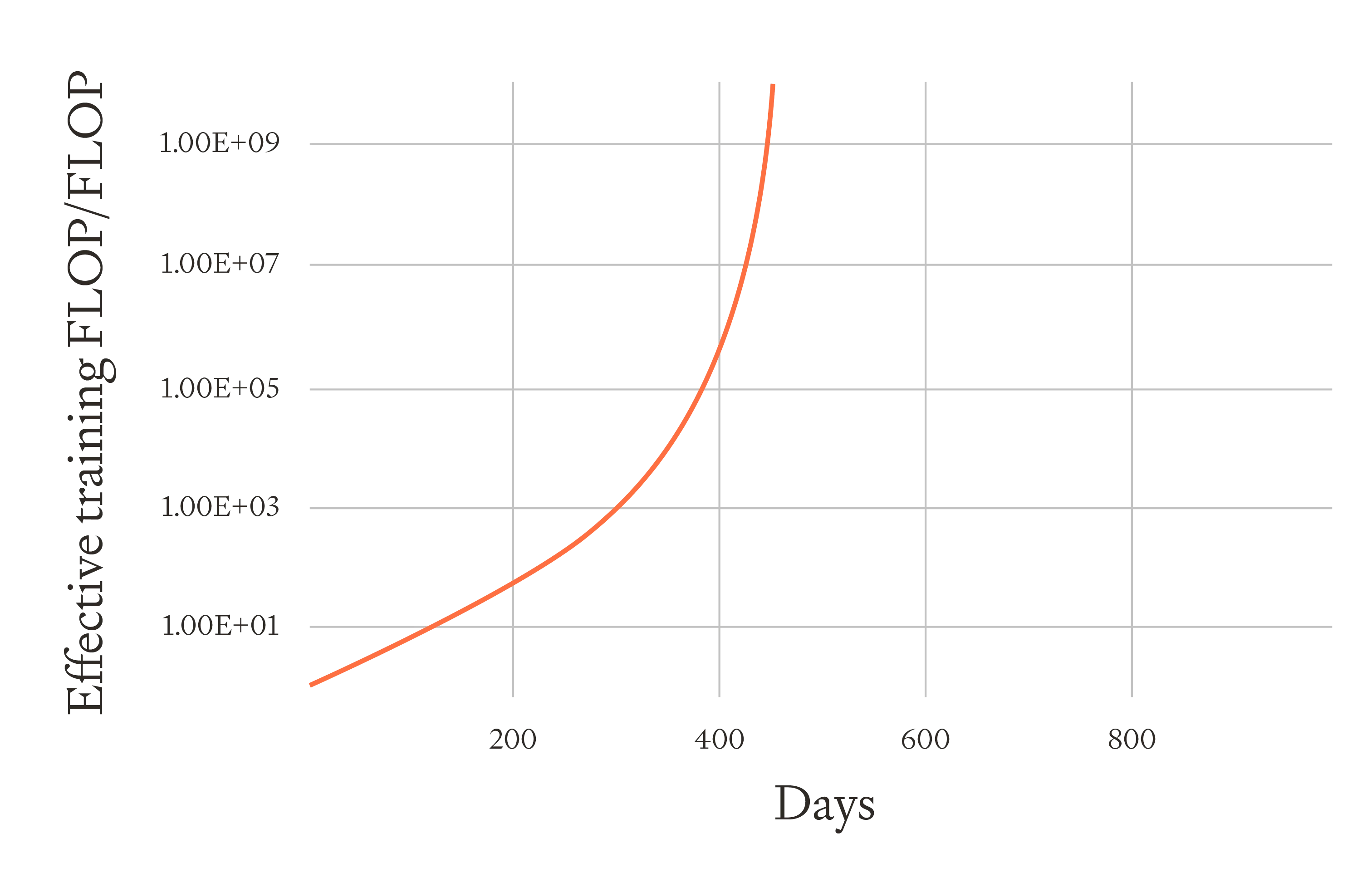
The productivity of the AI workforce increases in lock-step with the total cumulative effective training FLOP.6 So 100 days in the AIs are >3X more productive, and they improve training algorithms faster, which in turn allows them to increase the cumulative effective training FLOP faster, which in turns makes the AIs more productive.
Better training algorithms → faster increase in cumulative effective training FLOP → faster increase in AI productivity → faster discovering better training algorithms → faster increase in cumulative effective training FLOP.
After 200 days effective training FLOP has increased by 100X and the AI is 100X more productive.
Image
Ege Erdil has made a version of this model where you must retrain new models from scratch.
Software explosion without retraining – model explanation
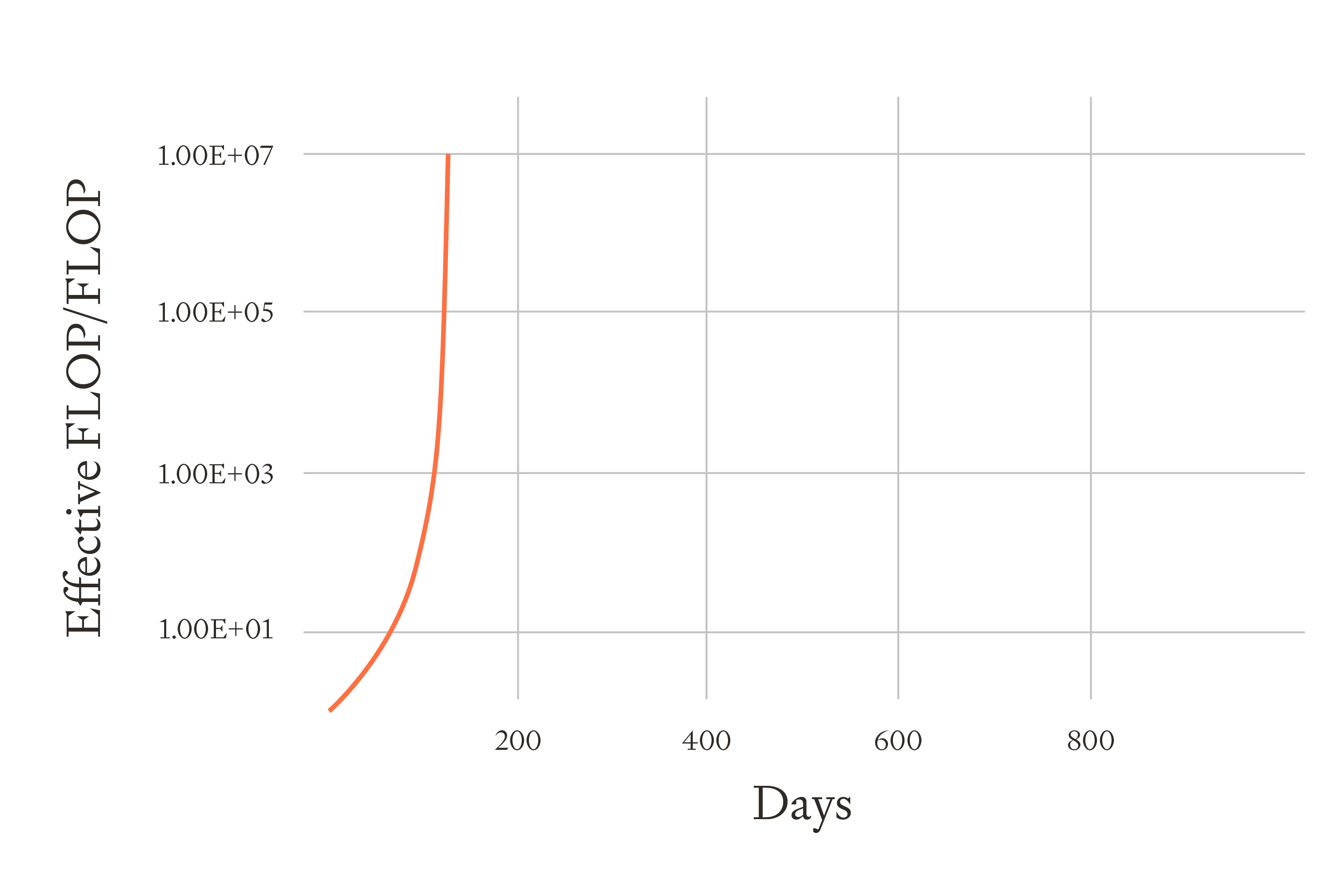
This sheet models the same SIE dynamics without retraining. Here, algorithmic innovations are applied instantaneously to improve the productivity of AI labour. This is appropriate for things like better prompting, better tool use, Auto-GPT, better inference efficiency via quantization, and perhaps also fine-tuning.
Image
Comparing the two scenarios
I used the same parameters in each sheet. In both cases, if you took the amount of cognitive labour available on the first day and held it fixed, it would take 35 days to double software.
Without retraining, it takes ~5 months for software to go to infinity. With retraining, it takes ~16 months. This is an increase of about 3X.
Other parameter values gave similar results:
| Software must double N times before the pace of improving AI software doubles7 | N = 4.3 | N = 3 | N = 2 | N = 1.5 |
|---|---|---|---|---|
| Initial software doubling time in months (holding cognitive labour fixed) | 1.4 | 1.2 | 1.1 | 0.5 |
| Months for software to go to infinity without retraining | 8 | 5 | 3 | 1.3 |
| Months for software to go to infinity with retraining | 27 | 16 | 10 | 4.6 |
| Multiplier that retraining applies on months to infinity | 3.4 | 3.2 | 3 | 3.5 |

Synthesis
Why are these slowdowns so much bigger than predicted in the theoretical analysis (which suggested retraining would only slow the number of doublings needed to double the pace progress from 5 to 6)?
My toy model assumes that training runs still take 3 months when we fully automate AI R&D and software progress is 10X faster.
But my theoretical model assumes that we gradually make training runs shorter as software progress speeds up. So my theoretical model would predict that training runs would have already become significantly shorter by the time software progress is 10X faster. And if training runs are already shorter, they will have less of a slowing effect on an SIE.
The toy model is more valid if we’ll suddenly and unexpectedly automate AI R&D, without shortening training times in advance. The theoretical analysis is more valid if you think we’ll gradually automate AI R&D, software progress will gradually speed up, and we’ll make our training runs gradually shorter and shorter as we do so.
So the more you expect sudden jumps, as in the toy model, the more you should expect retraining to slow the SIE. The more you expect gradual progress, the less of an impact retraining will have on the SIE.
Redoing the toy model with a shorter initial training run time is consistent with this story. We find that the results are more in line with the theoretical model.
Below are results with using a 30-day initial training run time instead of 100 days (and all other parameters the same):
| Each time cumulative software research doubles, software capabilities double… | N = 4.3 | N = 3 | N = 1.5 |
|---|---|---|---|
| Months for software to go to infinity without retraining | 8 | 5 | 1.3 |
| Months for software to go to infinity with retraining | 16 | 10 | 3.2 |
| Multiplier on duration (with shorter initial training time) | 2 | 2 | 2.5 |
Thanks to Max Dalton, Daniel Eth and Rose Hadshar for review.
